
데이터 샘플링은 대규모 모집단에서 일부 표본을 추출해 분석하는 과정으로, 보고서 정확도는 샘플링 방법의 대표성(모집단 유사도)에 따라 결정됩니다. 부적절한 샘플링은 편향(bias)을 유발해 보고서의 신뢰성을 떨어뜨립니다.
데이터 샘플링의 기본 개념
데이터 샘플링은 전체 모집단(population)에서 표본(sample)을 뽑아 분석 효율성을 높이는 기술입니다. 이는 비용 절감과 빠른 처리에 유용하지만, 표본이 모집단을 제대로 대표하지 못하면 결과가 왜곡됩니다.
샘플링 방법 분류
샘플링은 확률적(통계적)과 비확률적으로 나뉩니다. 확률적 방법은 각 데이터의 선택 확률을 미리 알 수 있어 통계적 추론이 가능하며, 정확도에 더 유리합니다.
| 방법 유형 | 주요 방법 | 특징 및 정확도 영향 |
|---|---|---|
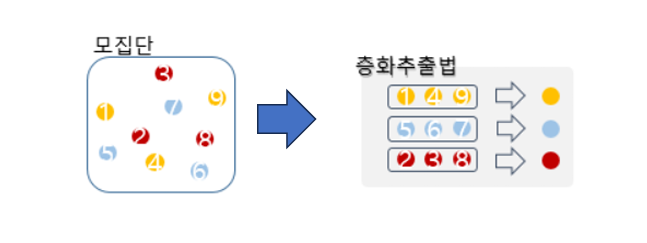
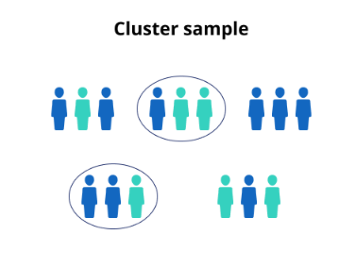
| 확률적 샘플링 | 단순 무작위(Simple Random): 전체에서 무작위 추출체계적(Systematic): 일정 간격 추출층화/유층/Stratified: 층별 무작위 추출군집/클러스터(Cluster): 군집 전체 사용 | 모집단 대표성 높음. 층화는 하위 그룹 균형 유지로 정확도 향상 |
| 비확률적 샘플링 | 편의(Convenience): 쉬운 데이터만 수집판단(Purpose): 주관적 선택 | 편향 발생 쉬움. 통계적 일반화 어려워 보고서 정확도 저하 |
보고서 정확도에 미치는 영향
- 대표성 부족 시 문제: 샘플이 모집단과 다르면 샘플링 편향(sampling bias) 발생. 예: 편의 샘플링은 특정 그룹만 반영해 전체 추정 오류.
- 정확도 높이는 팁:
- 층화 샘플링으로 다양성 확보.
- 샘플 크기 충분히(통계적 유의성 고려).
- 머신러닝에서는 학습/검증/테스트 분할로 과적합 방지.
- 대규모 데이터(예: Google Analytics)에서 샘플링은 필수지만, 하위 집합 분석으로 품질 저하 가능.
적절한 방법 선택 시 보고서의 신뢰성과 일반화 가능성이 크게 높아집니다.














Korea Traffic는 싱가포르에서 최고의 웹사이트 트래픽 서비스를 제공합니다. 우리는 웹사이트 트래픽, 데스크탑 트래픽, 모바일 트래픽, 구글 트래픽, 검색 트래픽, 전자상거래 트래픽, 유튜브 트래픽, 틱톡 트래픽 등 다양한 트래픽 서비스를 고객에게 제공합니다. 저희 웹사이트는 100% 고객 만족률을 자랑하므로, 대량의 SEO 트래픽을 온라인으로 자신 있게 구매하실 수 있습니다. 월 49,500 KRW만으로 즉시 웹사이트 트래픽을 증가시키고, SEO 성과를 개선하며, 매출을 증대시킬 수 있습니다!
트래픽 패키지 선택에 어려움이 있으신가요? 저희에게 연락주시면, 직원이 도움을 드리겠습니다.
무료 상담