
데이터 샘플링은 대규모 모집단에서 일부 표본을 추출해 분석하는 과정으로, 보고서 정확도는 샘플링 방법의 대표성(모집단 유사도)에 따라 크게 좌우됩니다.
데이터 샘플링의 기본 개념
데이터 샘플링은 전체 데이터를 처리하기 어려울 때 일부를 선택해 모집단을 대표하도록 하는 필수 단계입니다. 이는 비용 절감과 빠른 분석을 가능하게 하지만, 샘플링 편향(Sampling Bias)이 발생하면 보고서의 통계적 신뢰성과 일반화 가능성이 떨어집니다.
- 목적: 머신러닝에서는 학습/검증/테스트 데이터 분할로 사용되며, 통계 분석에서는 모집단 추정에 활용됩니다.
샘플링 방법 분류와 보고서 정확도 영향
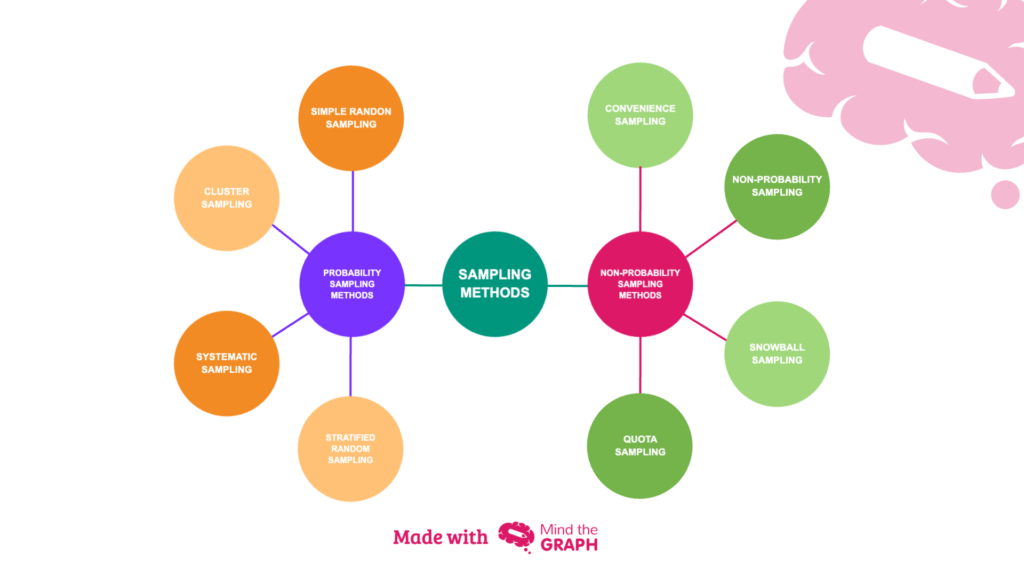
샘플링은 확률적(통계적) 샘플링과 비확률적(비통계적) 샘플링으로 나뉩니다. 확률적 방법은 각 데이터의 선택 확률이 알려져 있어 보고서 정확도가 높고, 모집단 일반화가 가능합니다. 반대로 비확률적 방법은 주관적 선택으로 편향 위험이 커 정확도가 낮습니다.
| 방법 유형 | 주요 방법 | 특징 및 정확도 영향 |
|---|---|---|
| 확률적 샘플링 | 단순 무작위(Simple Random): 무작위 추출계통(Systematic): 일정 간격 추출층화/유층(Stratified): 층별 비례 추출군집/클러스터(Cluster): 군집 전체 사용 | 모든 데이터에 확률 부여로 높은 대표성. 층화는 소수 그룹 정확도 향상. |
| 비확률적 샘플링 | 편의(Convenience): 쉬운 데이터 선택판단(Purpose): 주관적 선택 | 낮은 대표성, 통계 추론 불가. 편향으로 보고서 오류 증가. |
보고서 정확도 향상 팁
- 대표성 확보: 모집단 특성(예: 연령, 지역)을 고려한 층화 샘플링 사용.
- 편향 최소화: 샘플 크기 충분히 확보하고, 무작위성 유지.
- 검증: 리샘플링(Resampling)으로 안정성 확인.
- Google Analytics처럼 대규모 데이터에서 샘플링 시 하위 집합 분석으로 품질 저하 주의.
부적절한 샘플링(예: 편의 샘플링)은 보고서의 신뢰성을 떨어뜨려 잘못된 의사결정 유발할 수 있습니다. 분석 목적에 맞는 방법을 선택하면 정확도를 최적화할 수 있습니다.













Korea Traffic는 싱가포르에서 최고의 웹사이트 트래픽 서비스를 제공합니다. 우리는 웹사이트 트래픽, 데스크탑 트래픽, 모바일 트래픽, 구글 트래픽, 검색 트래픽, 전자상거래 트래픽, 유튜브 트래픽, 틱톡 트래픽 등 다양한 트래픽 서비스를 고객에게 제공합니다. 저희 웹사이트는 100% 고객 만족률을 자랑하므로, 대량의 SEO 트래픽을 온라인으로 자신 있게 구매하실 수 있습니다. 월 49,500 KRW만으로 즉시 웹사이트 트래픽을 증가시키고, SEO 성과를 개선하며, 매출을 증대시킬 수 있습니다!
트래픽 패키지 선택에 어려움이 있으신가요? 저희에게 연락주시면, 직원이 도움을 드리겠습니다.
무료 상담